Fourier-Lerobot:集成 Fourier 数据集的训练流程
基于令人印象深刻的 LeRobot 框架,fourier-lerobot增加了一个集成了 DP、ACT 和 IDP3 的训练流程。此外,为了支持人形机器人的开发,我们上传了 Fourier 数据集。有关 Fourier ActionNet 数据集的更多详细信息,请参阅Fourier ActionNet 数据集。我们还将提供一个脚本,用于将数据集转换为 LeRobotDatasetV2 格式。
LeRobot: 面向真实世界机器人最先进的人工智能
🤗 LeRobot 旨在为真实世界机器人技术提供 PyTorch 模型、数据集和工具。目标是降低机器人技术的入门门槛,让每个人都能通过共享数据集和预训练模型来贡献和受益。
🤗 LeRobot 包含已被证明可以迁移到真实世界的尖端方法,重点关注模仿学习和强化学习。
🤗 LeRobot 已经提供了一系列预训练模型、人工收集演示的数据集和模拟环境,让你无需组装机器人即可入门。在接下来的几周内,计划为市面上最经济实惠和功能强大的机器人增加越来越多的真实世界机器人技术支持。
🤗 LeRobot 在 Hugging Face 社区页面上托管预训练模型和数据集:huggingface.co/lerobot
模拟环境中的预训练模型示例
 |  |  |
| ACT policy on ALOHA env | TDMPC policy on SimXArm env | Diffusion policy on PushT env |
致谢
- 感谢 Tony Zhao, Zipeng Fu 和同事们开源了 ACT 策略、ALOHA 环境和数据集。我们的版本改编自 ALOHA 和 Mobile ALOHA。
- 感谢 Cheng Chi, Zhenjia Xu 和同事们开源了 Diffusion 策略、Pusht 环境和数据集,以及 UMI 数据集。我们的版本改编自 Diffusion Policy 和 UMI Gripper。
- 感谢 Nicklas Hansen, Yunhai Feng 和同事们开源了 TDMPC 策略、Simxarm 环境和数据集。我们的版本改编自 TDMPC 和 FOWM。
- 感谢 Antonio Loquercio 和 Ashish Kumar 的早期支持。
- 感谢 Seungjae (Jay) Lee, Mahi Shafiullah 和同事们开源了 VQ-BeT 策略,并帮助我们将代码库适配到我们的仓库中。该策略改编自 VQ-BeT 仓库。
安装
下载我们的源代码:
git clone https://github.com/huggingface/lerobot.git
cd lerobot
创建一个 Python 3.10 的虚拟环境并激活它,例如使用miniconda:
conda create -y -n lerobot python=3.10
conda activate lerobot
安装 🤗 LeRobot:
pip install -e .
注意: 根据你的平台,如果在此步骤中遇到任何构建错误,你可能需要安装 cmake 和 build-essential 来构建我们的一些依赖项。 在 Linux 上:
sudo apt-get install cmake build-essential
对于模拟,🤗 LeRobot 附带了可以安装为额外组件的 gymnasium 环境:
例如,要安装带有 aloha 和 pusht 的 🤗 LeRobot,请使用:
pip install -e ".[aloha, pusht]"
要使用 Weights and Biases 进行实验跟踪,请使用以下命令登录:
wandb login
(注意:你还需要在配置中启用 WandB。见下文。)
导览
.
├── examples # 包含演示示例,从这里开始了解 LeRobot
| └── advanced # 包含为已掌握基础知识的用户准备的更多示例
├── lerobot
| ├── configs # 包含配置类,其中包含所有可以在命令行中覆盖的选项
| ├── common # 包含类和实用工具
| | ├── datasets # 各种人工演示数据集:aloha, pusht, xarm
| | ├── envs # 各种模拟环境:aloha, pusht, xarm
| | ├── policies # 各种策略:act, diffusion, tdmpc
| | ├── robot_devices # 各种真实设备:dynamixel 电机, opencv 摄像头, koch 机器人
| | └── utils # 各种实用工具
| └── scripts # 包含通过命令行执行的函数
| ├── eval.py # 加载策略并在环境中评估它
| ├── train.py # 通过模仿学习和/或强化学习训练策略
| ├── control_robot.py # 遥操作真实机器人,记录数据,运行策略
| ├── push_dataset_to_hub.py # 将你的数据集转换为 LeRobot 数据集格式并上传到 Hugging Face hub
| └── visualize_dataset.py # 加载数据集并渲染其演示
├── outputs # 包含脚本执行的结果:日志、视频、模型检查点
└── tests # 包含用于持续集成的 pytest 实用工具
可视化数据集
查看example 1,它说明了如何使用我们的数据集类,该类会自动从 Hugging Face hub 下载数据。
你也可以通过从命令行执行我们的脚本来可视化 hub 上数据集的片段:
python lerobot/scripts/visualize_dataset.py \
--repo-id lerobot/pusht \
--episode-index 0
或者,对于本地文件夹中的数据集,使用 root 选项和 --local-files-only(在以下情况下,将在 ./my_local_data_dir/lerobot/pusht 中搜索数据集):
python lerobot/scripts/visualize_dataset.py \
--repo-id lerobot/pusht \
--root ./my_local_data_dir \
--local-files-only 1 \
--episode-index 0
它将打开 rerun.io 并显示摄像头视频流、机器人状态和动作,如下所示:
我们的脚本也可以可视化存储在远程服务器上的数据集。更多说明请参见 python lerobot/scripts/visualize_dataset.py --help。
LeRobotDataset 格式
使用 LeRobotDataset 格式的数据集非常简单。它可以从 Hugging Face hub 上的仓库或本地文件夹加载,例如 dataset = LeRobotDataset("lerobot/aloha_static_coffee"),并且可以像任何 Hugging Face 和 PyTorch 数据集一样进行索引。例如,dataset[0] 将从数据集中检索单个时间帧,其中包含观察结果和动作,作为可以馈送给模型的 PyTorch 张量。
LeRobotDataset 的一个特点是,我们可以通过设置 delta_timestamps 为一个相对于索引帧的相对时间列表,基于它们与索引帧的时间关系来检索多个帧,而不是通过索引检索单个帧。例如,使用 delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]},对于给定的索引,可以检索 4 帧:索引帧本身之前的 3 个"先前"帧(分别提前 1 秒、0.5 秒和 0.2 秒)以及索引帧本身(对应 0 条目)。有关delta_timestamps 的更多详细信息,请参见示例 1_load_lerobot_dataset.py。
在底层,LeRobotDataset 格式使用了几种序列化数据的方式,如果你计划更密切地使用这种格式,了解这些可能会很有用。我们尝试制作一种灵活而简单的数据集格式,以涵盖强化学习和机器人技术中存在的大多数特征和特性,无论是在模拟中还是在真实世界中,重点关注摄像头和机器人状态,但可以轻松扩展到其他类型的感官输入,只要它们可以用张量表示。
以下是典型的 LeRobotDataset 实例(使用 dataset = LeRobotDataset("lerobot/aloha_static_coffee") 实例化)的重要细节和内部结构组织。确切的特性会因数据集而异,但主要方面不会改变:
数据集属性:
├ hf_dataset: 一个 Hugging Face 数据集(由 Arrow/parquet 支持)。典型的特性示例:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': 指向 mp4 视频的路径, 'timestamp' (float32): 视频中的时间戳}
│ ├ observation.state (list of float32): 手臂关节的位置(例如)
│ ... (更多观察结果)
│ ├ action (list of float32): 手臂关节的目标位置(例如)
│ ├ episode_index (int64): 此样本的片段索引
│ ├ frame_index (int64): 此样本在片段中的帧索引;每个片段从 0 开始
│ ├ timestamp (float32): 片段中的时间戳
│ ├ next.done (bool): 指示片段的结束;每个片段的最后一帧为 True
│ └ index (int64): 整个数据集中的通用索引
├ episode_data_index: 包含每个片段开始和结束索引的 2 个张量
│ ├ from (1D int64 tensor): 每个片段的第一帧索引 — 形状 (num episodes,),从 0 开始
│ └ to: (1D int64 tensor): 每个片段的最后一帧索引 — 形状 (num episodes,)
├ stats: 一个包含数据集中每个特征的统计信息(最大值、平均值、最小值、标准差)的字典,例如
│ ├ observation.images.cam_high: {'max': 具有相同维度数的张量(例如,图像为 `(c, 1, 1)`,状态为 `(c,)`),等等。}
│ ...
├ info: 一个包含数据集元数据的字典
│ ├ codebase_version (str): 用于跟踪创建数据集时使用的代码库版本
│ ├ fps (float): 数据集记录/同步到的帧率
│ ├ video (bool): 指示帧是否编码为 mp4 视频文件以节省空间,或存储为 png 文件
│ └ encoding (dict): 如果是视频,则记录使用 ffmpeg 编码视频时使用的主要选项
├ videos_dir (Path): 存储/访问 mp4 视频或 png 图像的位置
└ camera_keys (list of string): 在数据集返回的条目中访问摄像头特性的键(例如 `["observation.images.cam_high", ...]`)
LeRobotDataset使用几种广泛使用的文件格式对其每个部分进行序列化,即:
-
hf_dataset 使用 Hugging Face datasets 库序列化为 parquet 格式存储
-
视频以 mp4 格式存储以节省空间
-
元数据以纯文本 json/jsonl 文件存储
数据集可以从 HuggingFace hub 无缝地上传/下载。要在本地数据集上工作,你可以使用 local_files_only 参数,并使用 root 参数指定其位置(如果它不在默认的 ~/.cache/huggingface/lerobot 位置)。
评估预训练策略
查看 示例 2,它说明了如何从 Hugging Face hub 下载预训练策略,并在其相应的环境中运行评估。
我们还提供了一个功能更强大的脚本来在同一 rollout 期间在多个环境上并行化评估。以下是一个在 lerobot/diffusion_pusht 上托管的预训练模型的示例:
python lerobot/scripts/eval.py \
--policy.path=lerobot/diffusion_pusht \
--env.type=pusht \
--eval.batch_size=10 \
--eval.n_episodes=10 \
--use_amp=false \
--device=cuda
注意:训练完你自己的策略后,你可以使用以下命令重新评估检查点:
python lerobot/scripts/eval.py --policy.path={OUTPUT_DIR}/checkpoints/last/pretrained_model
更多说明请参见 python lerobot/scripts/eval.py --help
训练你自己的策略
查看 示例 3,它说明了如何在 Python 中使用我们的核心库训练模型,以及 示例 4,它展示了如何从命令行使用我们的训练脚本。
要使用 wandb 记录训练和评估曲线,请确保你已经运行 wandb login 作为一次性设置步骤。然后,在运行上述训练命令时,通过添加 --wandb.enable=true 在配置中启用 WandB。
运行的 wandb 日志链接也会以黄色显示在你的终端中。以下是在浏览器中查看时的示例。请同时查看这里了解日志中一些常用指标的解释。
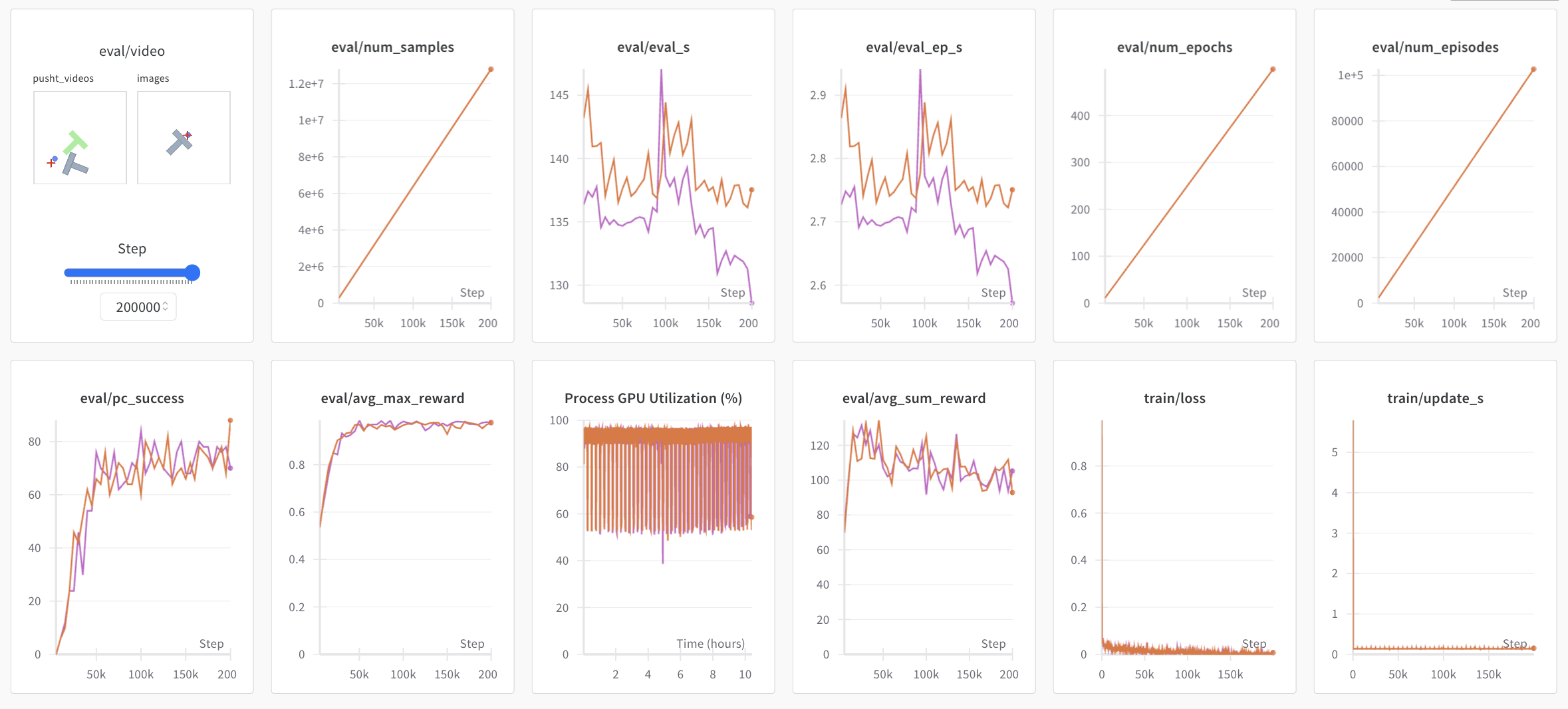
注意:为了提高效率,在训练期间,每个检查点只在少量片段上进行评估。你可以使用 --eval.n_episodes=500 来评估比默认值更多的片段。或者,训练后,你可能希望重新在更多片段上评估你的最佳检查点或更改评估设置。更多说明请参见 python lerobot/scripts/eval.py --help。
复现 state-of-the-art (SOTA)
我们在我们的 hub 页面 上提供了一些预训练策略,可以达到最先进的性能。 你可以通过从它们的运行中加载配置来复现它们的训练。只需运行:
python lerobot/scripts/train.py --config_path=lerobot/diffusion_pusht
即可复现 Diffusion Policy 在 PushT 任务上的 SOTA 结果。
贡献
如果你想为 🤗 LeRobot 做贡献,请查看我们的贡献指南
添加预训练策略(Pretrained Policy)
当你训练好一个策略后,可以使用形如 ${hf_user}/${repo_name} 的 Hub ID(例如 lerobot/diffusion_pusht)将其上传到 Hugging Face Hub。
首先,你需要找到实验目录下的 checkpoint 文件夹(例如 outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500)。
在该目录下有一个名为 pretrained_model 的子目录,其中应包含以下文件:
config.json:策略配置的序列化版本(遵循策略的 dataclass 配置)。model.safetensors:以 Hugging Face Safetensors 格式保存的torch.nn.Module参数。train_config.json:包含所有训练参数的综合配置文件。策略配置应与config.json完全一致。这对于想要评估你的策略或复现实验的人来说非常有用。
要将这些文件上传到 Hub,请运行以下命令:
huggingface-cli upload ${hf_user}/${repo_name} path/to/pretrained_model
可以参考 eval.py 了解其他人如何使用你的策略。
使用性能分析优化代码
下面是一个用于分析策略评估过程的代码示例:
from torch.profiler import profile, record_function, ProfilerActivity
def trace_handler(prof):
prof.export_chrome_trace(f"tmp/trace_schedule_{prof.step_num}.json")
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=2,
warmup=2,
active=3,
),
on_trace_ready=trace_handler
) as prof:
with record_function("eval_policy"):
for i in range(num_episodes):
prof.step()
# 在此插入要分析的代码,例如整个 eval_policy 函数的主体
引用
如果你想引用此项目,请使用以下 BibTeX 条目:
@misc{cadene2024lerobot,
author = {Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas},
title = {LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch},
howpublished = "\url{https://github.com/huggingface/lerobot}",
year = {2024}
}
此外,如果你使用了特定的策略架构、预训练模型或数据集,建议引用对应工作的原始作者论文,如下所示:
@article{chi2024diffusionpolicy,
author = {Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song},
title ={Diffusion Policy: Visuomotor Policy Learning via Action Diffusion},
journal = {The International Journal of Robotics Research},
year = {2024},
}
@article{zhao2023learning,
title={Learning fine-grained bimanual manipulation with low-cost hardware},
author={Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea},
journal={arXiv preprint arXiv:2304.13705},
year={2023}
}
@inproceedings{Hansen2022tdmpc,
title={Temporal Difference Learning for Model Predictive Control},
author={Nicklas Hansen and Xiaolong Wang and Hao Su},
booktitle={ICML},
year={2022}
}
@article{lee2024behavior,
title={Behavior generation with latent actions},
author={Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel},
journal={arXiv preprint arXiv:2403.03181},
year={2024}
}